这是一篇历史博客的汇总
这是我以前自己域名的博客网站所写的所有博客,现在服务器到期了,也没有时间维护多个平台的博客,故把历史的博客全都搬到这篇文章里。
[toc]
Hello 我是张念磊
Stephen Read是我的英文名
一直都有写博客的欲望,直到大四才开始写。
欢迎评论
python - 分析短信数据生成消费报告
原始数据片段展示:
1 | 来电,2017/1/5 上午11:55,95599,【中国农业银行】您尾号9672的农行账户于01月05日11时54分完成一笔支付宝交易,金额为-18.00,余额3905.35。, |
(数据来源-手机短信导出CVS格式)
目的
第一阶段的目的:分析基于中国农业银行的短信提醒,基于时间和银行账户余额的一个图表。
二阶段:想办法表现消费原因,消费金额。
三阶段:在处理语言方面可以灵活变动,不是简单地切片处理,而是基于处理自然语言的理解文意
以下是第一阶段的代码。如有问题或建议,欢迎交流!1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 22 22:13:20 2018
@author: mrzhang
"""
import csv
import os
import matplotlib.pyplot as plt
class DealMessage:
def __init__(self):
self.home_path = os.getcwd() # get absolute path
self.filename = self.home_path + "/message.csv"
def get_cvs_list(self):
''' get data for cvs '''
with open(self.filename) as f: # open file
reader = csv.reader(f)
list_read = list(reader)
return list_read
def get_yinghang_message_list(self):
''' del other data likes name, phone and others '''
total_list = self.get_cvs_list()
money_list = []
for each_line in total_list:
if each_line[2] == '95599':
del each_line[0] # remove useless data
del each_line[1]
del each_line[2]
each_line_list = each_line[1][37:].split(',')
each_line_list.insert(0, each_line[0])
money_list.append(each_line_list) # add to a new List
return money_list
def get_type_by_parameter(self, num):
''' there are 2 types of data, use len of data to distinguish it '''
money_list = self.get_yinghang_message_list()
first_list = []
for each in money_list:
if len(each) == num:
first_list.append(each)
return first_list
def deal_time_form(self, messages):
''' transform time form like 1995/02/07/02/23 '''
for each in messages:
correct_time = each[0].split()
date = correct_time[0]
time = correct_time[1]
time = time[2:]
shi, feng = time.split(":")
if time[0:2] == "下":
shi = int(shi) + 12
final_time = date + "/" + str(shi) + "/" + feng
each.insert(0, final_time)
def choose_message_by_time(self, is_before_0223):
''' reduce the difference betwoon different data, deal with time and money at the same time.'''
if is_before_0223:
num = 4
remove_num = 2
else:
num = 3
remove_num = 5
messages = self.get_type_by_parameter(num)
for each in messages:
# deal with time , transform time form like 1995/12/17/02/23
correct_time = each[0].split()
date = correct_time[0]
time = correct_time[1]
time = time[2:]
shi, feng = time.split(":")
if time[0:2] == "下": # transform time-form into 24h-form
shi = int(shi) + 12
final_time = date + "/" + str(shi) + "/" + feng
each.insert(0, final_time)
# deal with money
money = each[-1][remove_num:][0:-1]
each.insert(1, money)
return messages
def get_x_y(self):
''' get money and time '''
messages = self.choose_message_by_time(True)+self.choose_message_by_time(False)
time_list = []
money_list = []
for each in messages:
time_list.append(each[0])
money_list.append(float(each[1]))
return time_list[35::3], money_list
def draw_picture(self):
''' draw a picture about money change '''
x, y = self.get_x_y()
plt.figure(figsize=(16, 4)) # Create figure object
plt.plot(y, 'r') # plot‘s paramter(x,y,color,width)
plt.xlabel("Time")
plt.ylabel("Money")
plt.title("money")
plt.grid(True)
plt.show() # show picture
plt.savefig("line.jpg") # save picture
m = DealMessage() # get a class object
m.draw_picture() # draw picture
程序运行:
随意转载,欢迎交流!
第一章 开篇
友好的对话
在别人不会问问题时,引导他去问问题也是一个很大的学问,Jon与一个程序员问的问题而展开。
###问题
如何将1千万条记录排序?(都是七位的电话号码)最好是将时间控制在十秒钟左右,如果不行,几分钟也可以,但是不能超过十分钟,同时不可超过一兆的内存。
Jon先生要求我思考一分钟,并给他一个答案。我的答案有两个,一是使用链表的方式,运用插入排序的方法,二是使用规定排序的方法(尽管直至此时,我仍没有成功的完成固定排序,但我推荐他这么做的原因是其时间复杂度最低)下面向您简述我了解到的归并排序算法的原理,首先将数组分为两部分,然后将ab两部分分别排序,最后将ab两部分合并为一个数组。
如下图所示。
插入排序的过程如下:
将ab中待插入的元素作比较,将较小的插入L,然后将插入的数组定位器后移,继续比较两个数组的待插入元素,嗯,直到a与b中所有元素全部插入到L中,嗯,此时结束。当然以上并没有说明如何将ab数组排序,这里其实有一个很好的办法,就是将其分割若干次,直至每个数组都是单一元素数组,那么数组遍都是排序排好序的数组。
以上便是我的解答,非常奈斯!
下面是Python的实现代码。
1 | def marge(): |
####而Jon思考后的解决办法是使用位图,我觉得原因有以下几点:
1千万条记录又是用一兆的内存直接运行的,怕是不行。
复习一下组成原理的知识。
1 Byte = 8 bit
1 KB = 1024 Byte = 8 1024 bit
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
二进制数程序中,每个零或一就是一位。位就是bit。
假使这里运用八位二进制表示一个数字,且每个电话号码都为7位,则有(1024×1024×8) / (87) = 143000(Jon老师可能将1000视为1024)。
Jon的另一种方法似乎可以存放更多的数,即每个号码用32位二进制表示,则有(1000×1000*8) / 32 = 250000,即1M可以存放250000个号码,因为最大的7位数为9999999,便有9999999 / 250000 = 40。嗯,40次才能装得下1000万个电话号码。以上次多趟排序的空间大小分析,多趟排序的原理是第一趟排序中将0-250000之间的任何整数读入内存,并对着25万个整数排序,然后写到输出文件中,重复40次则排序完成。Jon说此问题若是采用归来排序可能需要几天的时间(包括写程序,调试,运行。我觉得晚上回去可以试一下)。
位图的方式更加简明记,即将大小为n的数用1占位表示第n个数是存在的,即array[1048256] = 1,即表示电话号码1048256存在。好了,下面来简述一下Jon的方法——位图的方法:
第一步就是初始化一个大小为一千万的shuzu。
第二部遍历输入文件。如果某个数存在则设其位置为1。
第三步,输出答案。
哇哇。真的简单明了,可惜可惜!为什么我们早点想到这个方法,脑中是有闪过这个想法的。但是觉得不成熟也没有在思考,而是转念去想归并排序这个方法了,是什么原因?我觉得是思维不愿意去思考的原因,前几天还看了关于开发思维的书籍,里面讲的:同时从好几个方面来思考方法。不要只从一面来思考。先不着急着否定了某个想法。先记下来。可惜可惜!
但是这个方法好像有问题。不是这个解法有问题,自己该用什么数据结构的存储,Jon首先说用字符串的方式。然后我说用数组的方式,我觉得都可以。好的牛皮!
习题1.6
2.问:如何使用位逻辑运算符(如与,或,移位)来实现位向量?
首先我因为不明白为向量是什么而搜索以下这个问题:“什么是位向量?”,我看了一下百度百科,CSDN的zeb_perfect以及远航先生的博客,我决定自己先来解决问题(笑)。因为百度的解释太深奥,不是看的很懂,zeb_perfect先生解读的可能有些偏差(无意冒犯),远航先生的解读过于深入,暂时不想看。但是我将二位的博客都添加到我的收藏夹下,待我先思考一番之后,且是全面的思考,定是全面的思考,再来拜读二位的博客。好了,废话不多说,先来探究问题,如果Jon先生在我面前,倘若有幸见到先生,那我一定会说:您这是问的什么鸡巴问题?可不可以不要那么抽象呢?而且也不明确。再读一遍问题:“如何使用位逻辑运算符(如与,或,移位)来实现位向量?”我还是不明白要问的是什么?原因以下1.可能是不明白什么是位向量?我的理解是位向量就是位图的延伸,使用多个位来表示一个单位,我们且将其称之为——位向量。哇哇哇~,如此简洁明了,怕是只有张某人能做出这一定义了,好了,不再废话,我的脑海中给出的答案现在有两个,
第一个是假设用四个位为一个单位,那么第一个与第二位的与可以表示一个单位的性质或者属性,那么这个这个位向量可以表示4+n个属性。
第二个通过使用位置位逻辑运算来生成其他几个位(这个也还是可以)。
好了,先到这里吃饭。
2008年8月14日
(昨晚将昨天的笔记通过讯飞输入法这样记录备忘录,然后又通过人工修正,最后发布到CSDN的博客上,此过程,大概共花费了我约一个小时的时间,其中语音录入20分钟,人工修正20分钟,重新排版30分钟。)
现在继续来看第三题。
第三题
题目是要我来比较不同的方法的运行时效率。方法包括:
- 自己系统上实现的位图排序。(嗯,因为昨天没有实现,所以这个暂时不能)
- 系统排序的运行时间;
- 习题一中排序的运行时间及潘盛内置函数的排序时间。
且Jon先生规定输入文件为一千万个,每个数不大于一千万。
第四题
吉先生很调皮,他说习题三中有一个小问题,如何生成小于n,且没有重复的k个整数?
至此,我吸取昨日的教训,决定从多个角度来回答这个问题。
解法一
可用攀升的内置函数生成随机数,即random.randint()因为这方法每次只能生成一个水技术,所以我们要将其稍微加工一下,使之成为深沉宿主的答案以下是我的潘神代码。
(由于忘记了Python的随机数生成的函数名,所以我搜索了一下,查到了random的模块,同时有了意外的发现这便是方法二。)
解法二
先上代码
‘’ import numpy
‘’
arr = numpy.arange(10)
numpy.random.shuffle(arr)
print(arr)
[7 4 8 3 2 9 0 1 5 6]
摘自CSDN christianashannon先生的博客https://blog.csdn.net/christianashannon/article/details/78867204
首先我是听说过numpy这个库的该库是由cpp实现的用来多用来实现科学计算(矩阵,向量),其中函数的性能较Python自带的同功能函数而言是提高了不少。(我目前没有考证,但是我同意该说法,因为是cpp的性能还是毋庸置疑的)
以下是我的解读:
经我猜测arange()函数便是生成数组0-n的函数。而np.random.shuffle(arr)便是将arr数列打乱,不知其原理为何?其效果如何?待我回去一检验,现在我还不知道如何查看python函数的源码,中午可以查一下。
经查:1
2
3import random
random.__file__
Out: '/Users/mrzhang/anaconda3/lib/python3.6/random.py'
即在ipyhton交互环境下使用 函数名.file (双下滑线)的方法即可查看文件位置
感谢Google-boy先生
https://www.cnblogs.com/ylHe/p/8621786.html
同时,这位先生还提供了另一种方法,看起来相当简洁。1
2
3print (numpy.random.permutation(10))
Out: [6 7 5 3 0 4 1 9 8 2]
(牛皮牛皮numpy不愧是作为科学计算用的,可能是因为科学计算也是常常用到随机数列这个功能,所以python的numpy库对其支持的如此人性化,我决定晚上要看一下这个numpy的函数的源码。)
以上两个方法便是库函数的方法。明天再来说说我自己的想法。
2008年8月15日。
昨晚并没有完成理想中的任务,同时昨天也没有完习题第三题的解答。自己思考的结果没有完成,并且解法二也没有自己在机器上实现,所以今天用25分钟来完成习题3的思考以后,便是对后面几题的解答好了,先读一下昨天的思考。
简单总结下昨天的思路,如下图所示。
1 | graph TD |
%% 直接生成数列:
%% 用列举的方法将全部结果。结果列出,然后用生成随机数的方法,在里面取一个作为生成出的随机数列,这方法虽虽然有点蠢,但是不是不可行。
%% 同余定理:
%% 用取模运算加上移位运算来将一个数生成一个与当今函数看起来完全没有关系的书。
在这里又打算用同余定理来解这道题,即暂时放弃其他的想法。同时决定要在今日的晚些时候来实现由我自己写的同余定理的代码,调试并计算程序运行的时间,并与mp外的标准库函数的运行时间作一个简单的比较,只要不是太缓慢我都可以接受。
好了开始设计,先写一个简单的文本,等上机后面再根据数据量再来调整,移位的原理即是乘除。二进制的移位是乘除2,十进制的移位便是乘除10
首先用97 98 99来当做实验数据。
公式如下。
result = (n % 2333 * 13 + 56) // 10
%% 因计算器没有去于这个运算符,所以只能中午晚上用电脑做。
练习五:
如果严格规定空间为1M,那么该如何处理算法与运行时间又是多少?
我能想到的是两方面,一是优化现有的代码,第二重新设计。
%% (很好,讲想法都列出来了,有很大的进步。)
先说优化,我觉得可以将其分为两次来操作,因为共有一千万条数据,第一次就是先遍历前500万个,然后将第二次遍历后后面的500万个。
1 M = 1000 KB = 1000000 B = 8000000 bit
方法是可行的,时间就是以前的两倍,因为遍历了两次。
再说重新设计,我觉得也可以。因为这个问题是一个实际问题,它数据密集度可能很高,那么我们便可以将n个连续的1用二进制表示,那么便可节约很大的空间。
比如将连续的三个一转换成二进制,
例:数据[1,2,3,5,8,13]
则有,011101001000100 ,用(11)(二进制的3)表示有3个1是连续的
则有,01101001000100
可能这组数据不能说明问题,那我们来换一组数据。
[1,2,3,4,5,7,9,12,13,14,15]
0111110101001111
0,101,010100,100,
好了,现在出问题了,因为都是0与1,怎么判断那几个零与一是连起的就是个问题了。所以我觉得我们有必要引入‘n位二进制’这个概念了,那么问题来了,这个n该设置为多少?
2^32 = 4297967295
32位好像是足够了。
1M / 32bit = 250000
1M内存可以存放25万个int字节(int为四个字节,每个字节8位,则int为32位)
下面便要考虑数据的连续性,如果程序员先生的数据有25万次不连续,那么便不可以用这个方法,一千万个数,25万次不连续可能还是有点困难的吧。
25万 / 1千万 = 1 / 400 = 0.25 %
若连续的概率要超过99.75%,即400个数才可以有一次断裂,我觉得这还是难为人家了,但是将此方法写出来,便是有意义的。
1.使用动态拼接SQL查询
1 | /** |
2. 使用存储结构
存储结构的优势是速度快,因为sql是编译好的,只要加上查询的字段就可以了
MySQL的存储过程大概长这样:
1 | CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int) |
调用存储结构的方法
1 | /** |
Jpa调用存储结构的方法略显复杂这里就不写了
3….(待续)
由于国内关于myPagination插件的文档并不多,由于参照官方给的文档一直出现问题,
所以自己摸索出了一种新的食用方法。
定义全局变量和默认搜索条件
1 | var searchJson = {}; |
ajax请求数据并渲染
1 | //ajax获取要显示的数据 |
最重要的是最后一行代码:
1 | pagin.init(); |
初始化,即让上面两行修改的总页数和总条数参数生效
搜索按钮点击事件
1 | //弹出搜索框 |
参考文档:
myPagination插件
天气冷了,多买几双厚袜子因该是最容易提升幸福感的事了。晚上洗完澡穿上厚袜子组图书馆看会儿书真的是很幸福了。
洗澡的时候想到的,做什么事都不要一开始用尽全力。
一是因为可能用力过猛,导致后面没力气了,这很尴尬;
二是如果不能坚持下去,那么别人就会觉得你虎头蛇尾,或是三分钟热度。
做一件事情因该把握好节奏,
开始的时候稳着点,
该用力的时候用力,
在合适的时候用力,
在合适的时间收尾。
工作是这样,爱情也是。
环境:
- IDEA
- JDK8
- Spring Boot
- MySQL
- Spring Data JPA
在数据库中创建一个存储过程
1 | CREATE PROCEDURE GetStudent(IN ageMin int, IN gradeMin int) |
简单解释:
第一行中的GetStudent 是过程名,括号中的是参数,IN代表传入参数,OUT是传出参数, ageMin是参数名,int是参数类型(参数类型需是数据库中的参数类型)。
BEGIN和END中间的就是SQL语句
在数据库中调用:1
call GetStudent(1,2);
使用spring data jpa调用这个存储过程:
步骤:
- 创建一个实体类
- 在实体类中使用注解的方式绑定数据库中的存储过程
调用这个存储过程
先上代码
实体类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package com.zhang.demo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
@Entity
@NamedStoredProcedureQuery(name = "GetStudent", procedureName = "GetStudent",
resultClasses = {Student.class},
parameters = {
@StoredProcedureParameter(mode = ParameterMode.IN, name = "ageMin", type = Integer.class),
@StoredProcedureParameter(mode = ParameterMode.IN, name = "gradeMin", type = Integer.class)
})
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
@Id
@GeneratedValue
private Long id;
private String no;
private String name;
private Integer grade;
private Integer age;
}说明:
@NamedStoredProcedureQuery 申明一个存储过程name属性是给这个存储结构起一个名字 procedureName属性是存储结构在数据库中的名字 resultClasses属性声明这个存储过程返回的结果集的类型 parameters属性声明这个存储结构的参数 (如果存储过程返回的是一个临时表,那么resultClasses对应的临时表的字段要与数据库中的字 段匹配,匹配不意味着完全相等而是:下划线->驼峰,因为它使用的是jpa的规范)
@Entity注解的作用是声明这是一个实体类
下面三个注解是插件lombok的方法
@Data 生成getter and setter方法
@NoArgsConstructor 生成无参的构造函数
@AllArgsConstructor 生成全参的构造函数
使用lombok插件的方法很简单:
先添加依赖(使用Maven构建项目)1
2
3
4<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
然后在IDEA的 setting -> Plugins 搜索lombok点击安装
最后重启IDEA
@Id与@GeneratedValue是JPA的注解,意思是声明id字段是主键,且设置自增
调用:
1 | package com.zhang.demo; |
因为是demo所以就粗糙一点没有使用service层,直接在Controller中调用
获取spring容器中的EntityManager1
2@PersistenceContext
private EntityManager entityManager;
createNamedStoredProcedureQuery()方法创建一个查询对象
setParameter()来设置参数的值
getResultList()方法来获取结果集
完整的代码:https://github.com/ZhangnLei/demo-for-procedure-query.git
between的用法1
2
3
4
5@Query(nativeQuery = true,
value = "select * from z_cashier_data" +
"where abstract_code = ?1 " +
"and time BETWEEN ?2 and ?3")
Page<CashierData> findAllabcd(String code, Date start, Date end, Pageable pageable);//函数名随意
相当于下面这条1
Page<CashierData> findAllByAbstractCodeAndTimeBetween(String code, Date start, Date end, Pageable pageable);
in的用法1
2
3@Modifying
@Query(nativeQuery = true, value = "DELETE from z_cashier_data where id in (:ids)")
void deleteIn(@Param("ids") List<Long> ids);//函数名随意
相当于下面这条1
void deleteByIdIn(List<Long> ids);
}
1 | 场景自动生成代码,要根据上一条记录的代码,代码要为上一条代码+1 |
select * FROM z_cashier_data
where id = (SELECT max(z_cashier_data.id) from z_cashier_data where abstract_code = “1001”);1
2ajax的async这个属性默认是true:异步,false:同步。
区别:
$.ajax({
type: “GET”,
dataType: ‘json’,
async: false,
contentType: ‘application/json;charset=utf-8’,
url: ctx+”/admin/cashierManager/getCode”,
success: function(msg){
if (msg.code === 0){
newCode = msg.data;
}
}
});1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23有了这个属性可以相对的减少代码运行书序问题,但是如果用的太多,页面假死次数太多。这样反而导致用户体验不佳~!
$.Ajax()中 async 和success的官方的解释:
async
Boolean
Default: true
By default, all requests are sent asynchronous (e.g. this is set to true by default).
If you need synchronous requests, set this option to false. Note that synchronous
requests may temporarily lock the browser, disabling any actions while the request
is active.
success
Function
A function to be called if the request succeeds. The function gets passed two
arguments: The data returned from the server, formatted according to the 'dataType'
parameter, and a string describing the status. This is an Ajax Event.
在这里,async默认的设置值为true,这种情况为异步方式,就是说当ajax发送请求后,在等待server端返回的这个过程中,前台会继续 执行ajax块后面的脚本,直到server端返回正确的结果才会去执行success,也就是说这时候执行的是两个线程,ajax块发出请求后一个线程 和ajax块后面的脚本(另一个线程)例:
$.ajax({
type:”POST”,
url:”Venue.aspx?act=init”,
dataType:”html”,
success:function(result){ //function1()
f1();
f2();
}
failure:function (result) {
alert(‘Failed’);
},
}
function2();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
在上例中,当ajax块发出请求后,他将停留function1(),等待server端的返回,但同时(在这个等待过程中),前台会去执行function2(),也就是说,在这个时候出现两个线程,我们这里暂且说为function1() 和function2()。
当把asyn设为false时,这时ajax的请求时同步的,也就是说,这个时候ajax块发出请求后,他会等待在function1()这个地方,不会去执行function2(),知道function1()部分执行完毕。
我有一个问题,js时单线程的,那么为什么ajax可以多线程?
参考:[https://www.cnblogs.com/xmphoenix/archive/2011/11/21/2257651.html](https://www.cnblogs.com/xmphoenix/archive/2011/11/21/2257651.html)
### 问题:
使用JS的函数时,将对象类型的值作为参数传到函数内,且在函数内修改了该参数,导致原值被修改。
### 原因:
JS函数的参数有两种类型,基本类型和引用类型。传参时会传入一个该值的拷贝,且该拷贝类型为浅拷贝
#### 浅拷贝与深拷贝
首先,浅拷贝和深拷贝都只针对于像Object, Array这样的复杂对象,
区别:浅拷贝只复制对象的第一层属性、深拷贝可以对对象的属性进行递归复制
### 解决办法:
不在方法里修改引用性参数的值,如果一定要这么做那就创建一个拷贝
### 创建深拷贝拷贝的方法:
#### 1.自己写
deepCopy (o, c) {
c = c || {}
for (let i in o) {
if (typeof o[i] === ‘object’) {
// 需要深拷贝
if (o[i].constructor === Array) {
// 数组
console.log(‘是数组’)
c[i] = []
} else {
// 对象
console.log(‘是对象’)
c[i] = {}
}
this.deepCopy(o[i], c[i])
} else {
c[i] = o[i]
}
}
return c
}1
2
3
4
5
6
7
8
9
10
11
12
#### 1.JQuery的extend()方法
$.extend( [deep ], target, object1 [, objectN ] )
deep表示是否深拷贝,为true为深拷贝,为false,则为浅拷贝
target Object类型 目标对象,其他对象的成员属性将被附加到该对象上。
object1 objectN可选。 Object类型 第一个以及第N个被合并的对象。
示例:
// 期初余额的数据
var insertRow = {
endBalance: $(“#beginBalance”).val(),
type: “期初余额”
};
printTable(insertRow);
function printTable(insertRow) {
var data = new Array();
newRow = $.extend(true, insertRow.type, insertRow);
newRow.endBalance = insertRowBalance;
data.unshift(newRow);
}1
2
#### 2.使用JSON对象的parse()和stringify()方法
function deepClone(obj){
let _obj = JSON.stringify(obj),
objClone = JSON.parse(_obj);
return objClone
}
let a=[0,1,[2,3],4],
b=deepClone(a);
a[0]=1;
a[2][0]=1;
console.log(a,b);1
2
3
4
5
6
7
8
9
10
还有尽量不用全局变量
参考:
[https://www.cnblogs.com/echolun/p/7889848.html](https://www.cnblogs.com/echolun/p/7889848.html)
[https://blog.csdn.net/qq_28978893/article/details/79272422 ](https://blog.csdn.net/qq_28978893/article/details/79272422)
### 设置高度为灵活高度
添加高度属性
height: $(window).height() 0.68,1
2
3
4
5
### 添加数据统计
分为两步:
第一步
showFooter: true,1
第二步
footerFormatter: function (value) {
var count = 0;
for (var i in value){
count += parseFloat(value[i].hBorrow);
}
return xiaoshu(count);
}1
2
### 不显示某些列
onLoadSuccess: function(){
if(type == 2){
$table.bootstrapTable(‘hideColumn’, ‘abstractName’);
}
}1
2
### 给每一行添加属性
rowAttributes: function (row, index) {
return {“data-acc”: row.acc};
}1
完整示例代码
$(‘#table’).bootstrapTable({
// data:data,
idField: ‘id’,
dataType: ‘jsonp’,
height: $(window).height() 0.68,//设置高度为页面的68%
showFooter: true,//设置启用统计功能
columns: [
{field: ‘id’, title: ‘科目代码’, width: ‘150px’,
footerFormatter: function (value) {
return “汇总”;
}},
{field: ‘subjectName’, title: ‘科目名称’,},
{field: ‘dir1’, title: ‘方向’, width: ‘40px’, align: ‘center’},
{field: ‘startBalance’, title: ‘期初余额’, align: ‘right’, width: ‘140px’,
footerFormatter: function (value) {
var count = 0;
for (var i in value){
count += parseFloat(value[i].startBalance);
}
return xiaoshu(count);
}},
{field: ‘hBorrow’, title: ‘借方发生’, align: ‘right’, width: ‘140px’,
footerFormatter: function (value) {
var count = 0;
for (var i in value){
count += parseFloat(value[i].hBorrow);
}
return xiaoshu(count);
}},
{field: ‘hLoad’, title: ‘贷方发生’, align: ‘right’, width: ‘140px’,
footerFormatter: function (value) {
var count = 0;
for (var i in value){
count += parseFloat(value[i].hLoad);
}
return xiaoshu(count);
}}
],
showHeader: true,
onPreBody: function (data) {
if (data.length > 0){
for (var i in data) {
data[i].startBalance = xiaoshu(data[i].startBalance);
data[i].hBorrow = xiaoshu(data[i].hBorrow);
data[i].hLoad = xiaoshu(data[i].hLoad);
}
}
},
//在哪一列展开树形
treeShowField: ‘id’,
//指定父id列
parentIdField: ‘pid’,
onResetView: function (data) {
$table.treegrid({
initialState: ‘collapsed’,// 所有节点都折叠
treeColumn: 0,
onChange: function () {
$table.bootstrapTable(‘resetWidth’);
}
});
},
rowStyle: function (row, index) {
return {classes: ‘setli’};
},
//给每一行添加属性
rowAttributes: function (row, index) {
return {“data-acc”: row.acc};
}
});
1 |
|
function printTable(insertRow) {
$table.bootstrapTable({
method: “POST”,
cache: false,
url: ctx + “/admin/cashierManager/getCashierDataList”,
contentType: “application/x-www-form-urlencoded”,
pageSize: 5,
pageNumber: 1,
pageList: [5, 10, 20],
dataSidePagination: “server”,
sidePagination: “server”,
dataType: ‘json’,
pagination: true, //分页
paginationLoop: false,
showPaginationSwitch: false,
paginationPreText: ‘上一页’,
paginationNextText: ‘下一页’,
responseHandler: function (res) {
return {
“rows”: res.content,
“total”: res.totalElements
};
},
columns: [
{field: ‘code’, title: ‘单据号’, width: ‘100px’, align: ‘center’,},
{field: ‘time’, title: ‘日期’, width: ‘100px’, align: ‘center’,},
{field: ‘type’, title: ‘单据类型’, width: ‘100px’, align: ‘center’,},
{field: ‘abstractName’, title: ‘摘要’, align: ‘center’,},
{field: ‘borrow’, title: ‘借方’, width: ‘130px’, align: ‘right’,},
{field: ‘loan’, title: ‘贷方’, width: ‘130px’, align: ‘right’,},
{field: ‘endBalance’, title: ‘余额’, width: ‘130px’, align: ‘right’,},
],
onPreBody: function (data) {
console.log(data); // 1
if (data.length > 0){
// console.log(data);
var balance = accAdd(insertRow.endBalance, 0);
var insertRowBalance = accAdd(data[0].endBalance, balance);
for (var i in data) {
if (i == 0){
balance = balance + data[i].endBalance;
}
balance = balance + data[i].borrow - data[i].loan;
data[i].endBalance = balance;
}
//如果是第一页,要在行首加一条数据
if (this.pageNumber == 1) {
newRow = $.extend(true, insertRow.type, insertRow);
newRow.endBalance = insertRowBalance;
data.unshift(newRow);
}
}
}
});
}
1 |
|
if (data.length > 0){
}
1 |
|
$table.bootstrapTable(‘load’,data);1
2
3方法无效;(确认可以查询到数据且打印在前端但是没有渲染到bootstrap table上)
解决办法:
table.bootstrapTable(‘removeAll’);
table.bootstrapTable(‘append’,data.data);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18使用先清空再添加的方法解决该问题。
重装mysql的时候在删除玩文件、注册表之后一定记得重启然后再安装新的软件
最近金常用到的,写下来。
最近需要经常操作list 数据库查询出来的list需要加工,然后返回给前端
其中加工的过程有常见的两种操作, 一是修改二是删除
如果List的元素是对象,那么修改他没有关系,直接for循环遍历,如果是基础类型,那么最好还是new一个数组,然后来接收他吧
如果是删除的话for循环遍历恐怕不行,因为删除的过程中改变了List的索引,可能会报out of bounds 的错
那么迭代的方法便可以解决这一个问题
代码如下:
Iterator
while(iterator.hasNext()){
AccountBalance balance = iterator.next();
if(balance.getStartBalance().compareTo(BigDecimal.ZERO) == 0 && balance.getEndBalance().compareTo(BigDecimal.ZERO) == 0){
iterator.remove();
}
}1
2
3
4
问题描述:
迁移系统后使用bootstrapTable的load方法加载数据
$table.bootstrapTable(‘load’,data);1
2
3方法无效;(确认可以查询到数据且打印在前端但是没有渲染到bootstrap table上)
解决办法:
table.bootstrapTable(‘removeAll’);
table.bootstrapTable(‘append’,data.data);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80使用先清空再添加的方法解决该问题。
##Redis学习笔记 2018-4-3
###关于Redis的小故事:
很有意思,Redis是由MySQL的开发者开发的,因为他对MySQL的性能不满意,故自己和另一位开发者写了Redis
###NoSQL
not only sql 非关系型数据库
###Mac下安装及启动Redis
一、下载安装
百度 redis下载,进官网[https://redis.io/]或中文官网[http://www.redis.cn]下载。
二、本地存放
本地新建个redis文件夹,把下载的文件加压到redis文件夹中。
三、安装
进入解压的redis文件夹中,编译安装,结果大致如图
输入命令:
cd redis-x.x.x
sudo make install (会提示输入电脑密码)
四、启动redis服务
进入 src文件夹 后 执行启动命令 如图
cd src
./redis-server
五、启动redis客户端实测
新开个终端,进入到src文件夹,执行命令 如图
./redis-cli //表示启动redis客户端
set admin echoRedis // 设置 key为admin value为echoRedis(redis的set语法)
//返回结果OK为 设置成功
get admin // 取 key为admin的value值(redis的get语法)
//返回结果为 echoRedis(我们设置的值)
【表示redis客户端测试成功】
六、简单的和java结合
public Object demo1(){
Jedis jedis = new Jedis("localhost");
jedis.set("name","zhang");
String value = jedis.get("name");
System.out.println(value);
jedis.close();
return value;
}
七、结束
###Redis数据类型(五种)
字符串 string
哈希 hash
字符串列表 list
字符串集合 set
有序字符串集合 sorted set
###Code From imook
/**
* 单实例的测试
*/
public Object demo1(){
Jedis jedis = new Jedis("localhost");
jedis.set("name","zhang");
String value = jedis.get("name");
System.out.println(value);
jedis.close();
return value;
}
/**
* 连接池的方式
*/
public Object demo2(){
//或得连接池的配置对象
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数
config.setMaxTotal(30);
//最大空闲连接数
config.setMaxIdle(10);
//或得连接池
JedisPool jedisPool = new JedisPool(config,"localhost",6379);
//或得对象核心
Jedis jedis = null;
try{
//获得连接池
jedis = jedisPool.getResource();
//设置数据
jedis.set("name","zhang");
//获取数据
String value = jedis.get("name");
System.out.println(value);
return value;
}catch (Exception e){
e.printStackTrace();
}finally {
//释放资源
if (jedis != null){
jedis.close();
}
if (jedisPool != null){
jedisPool.close();
}
}
return null;
}
1 | ### 1.使用ajax传递对象 |
function save(status) {
var dataList = $table.bootstrapTable(“getData”, true);
var obj = dataList[0];
obj.status = status;
obj.opinion = $(“#opinion”).val();
$.ajax({
type: "post",
url: "/admin/warning/approve/save",
contentType: 'application/json;charset=utf-8',
data: JSON.stringify(obj),
dataType: "json",
success: function (msg) {
console.log(msg);
if (msg.code == 0) {
layer.msg(msg.message, {icon: 1, time: 1000}, function () {
var index = parent.layer.getFrameIndex(window.name);
parent.layer.close(index);
});
} else {
layer.msg(msg.message, {icon: 2, time: 1000})
}
}
});
}1
后端代码:
/**
- 保存
- @param costStr
@return
*/
@RequestMapping(“/save”)
@ResponseBody
public JsonResult save(@RequestBody String costStr){
CostApplication costApplication = JSON.parseObject(costStr, new TypeReference() {});
costApplicationService.save(costApplication);
return JsonResult.success();
}1
2### 2.使用post方式传递多个参数
前端代码:function saveOrSubmit(type) {
var dataList = $table.bootstrapTable(“getData”, true);
console.log(dataList);
console.log($(“#kj”).val());
$.ajax({type: "post", url: "/admin/warning/apply/save", data: { saveType: type, dataListStr: JSON.stringify(dataList), bzy: $("#bzy").val(), kj: $("#kj").val(), cn: $("#cn").val(), }, dataType: "json", success: function (msg) { // msg = JSON.parse(msg); console.log(msg); if (msg.code == 0) { layer.msg(msg.message, {icon: 1, time: 2000}, function () { var index = parent.layer.getFrameIndex(window.name); parent.layer.close(index); }); } else { layer.msg(msg.message, {icon: 2, time: 2000}) } }});
}1
后端代码:
/**
- 保存
- @return
*/
@RequestMapping(“/save”)
@ResponseBody
public JsonResult save(Integer saveType, String dataListStr, String reason, String bzy, String kj, String cn, HttpSession session, ModelMap map){
ListdataList = readListValue(dataListStr, CostApplication.class);
if (dataList != null){
}for (CostApplication c: dataList){ if (saveType != null){ c.setStatus(saveType); } if (reason != null){ c.setReason(reason); } if (bzy != null){ c.setBzy(bzy); } if (kj != null){ c.setKj(kj); } if (cn != null){ c.setCn(cn); } } costApplicationService.save(dataList); return JsonResult.success();
return JsonResult.failure(“操作失败!”);
}$.ajax({1
2
3
4
5
### 同步与异步
ajax的async这个属性默认是true:异步,false:同步。
使用示例:
});type: "GET", dataType: 'json', async: false, contentType: 'application/json;charset=utf-8', url: ctx+"/admin/cashierManager/getCode", success: function(msg){ if (msg.code === 0){ console.log(msg.data); } }$.ajax({1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23这个属性可以相对的减少代码运行书序问题,但是如果用的太多,页面假死次数太多。这样反而导致用户体验不佳~!
$.Ajax()中 async 和success的官方的解释:
async
Boolean
Default: true
By default, all requests are sent asynchronous (e.g. this is set to true by default).
If you need synchronous requests, set this option to false. Note that synchronous
requests may temporarily lock the browser, disabling any actions while the request
is active.
success
Function
A function to be called if the request succeeds. The function gets passed two
arguments: The data returned from the server, formatted according to the 'dataType'
parameter, and a string describing the status. This is an Ajax Event.
在这里,async默认的设置值为true,这种情况为异步方式,就是说当ajax发送请求后,在等待server端返回的这个过程中,前台会继续 执行ajax块后面的脚本,直到server端返回正确的结果才会去执行success,也就是说这时候执行的是两个线程,ajax块发出请求后一个线程 和ajax块后面的脚本(另一个线程)例:
type:”POST”,
url:”Venue.aspx?act=init”,
dataType:”html”,
success:function(result){ //function1()
}f1(); f2();
failure:function (result) {
},alert('Failed');
}
function2();layer.msg(“操作成功”, {time:2000, icon:1}); //icon:0-21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
在上例中,当ajax块发出请求后,他将停留function1(),等待server端的返回,但同时(在这个等待过程中),
前台会去执行function2(),也就是说,在这个时候出现两个线程,我们这里暂且说为function1() 和function2()。
当把asyn设为false时,这时ajax的请求时同步的,也就是说,这个时候ajax块发出请求后,他会等待在function1()这个地方,
不会去执行function2(),直到function1()部分执行完毕。
### $.ajax()方法常用参数详解
$.ajax()方法是jQuery最底层的Ajax实现。它的结构为:
$.ajax(options)
该方法只有一个参数,但是这个对象里包含了$.ajax()方法所需要的请求设置以及回调函数等信息,参数以key/value的形式存在,所有的参数都是可选的。
常用参数见下表:
1.url
要求为String类型的参数,(默认为当前地址)发送请求的页面。
2.type
要求为String类型的参数,请求方式(post或get)默认为get。注意其他http请求方法,例如put和delete也可以使用,但仅部分浏览器支持。
3.data
要求为Object或String类型的参数,发送到服务器的数据。如果不是字符串,将自动转换为字符串格式。get请求中将附加在URL后。防止这种自动转换,可以查看
processData选项。对象必须为key/value格式,例如{foo1:"bar1",foo2:"bar2"}转换为&foo1=bar1&foo2=bar2。
如果是数组,JQuery将自动为不同值对应同一个名称。例如{foo:["bar1","bar2"]}转换为&foo=bar1&foo=bar2。
4.contentType
要求为String类型的参数,当发送信息至服务器时。内容编码类型默认为"application/x-www-form-urlencoded"。该默认值适合大多数应用场合。
5.dataType
要求为String类型的参数,预期服务器返回的数据类型。如果不指定,jQuery将自动根据HTTP包的mine信息返回responseXML或responseText,
并作为回调函数参数传递。可用的类型如下:
xml:返回XML文档,可用jQuery处理。
html:返回纯文本HTML信息;包含的script标签会在插入DOM时执行。
script:返回纯文本javascript代码。不会自动缓存结果,除非设置了cache参数。注意在远程请求时(不在同一个域下),所有post请求都将转为get请求。
json:返回JSON数据。
jsonp:JSON格式。使用JSONP形式调用函数时,例如myurl?callback=?,JQuery将自动替换后一个“?”为正确的函数名,以执行回调函数。
text:返回纯文本字符串。
6.success
要求为Function类型的参数,请求成功后调用的回调函数,有两个参数。
(1)由服务器返回,并根据dataType参数进行处理后的数据。
(2)描述状态的字符串。
function(data,textStatus){
//data可能是xmlDoc、jsonObj、html、text等
this; //调用本次ajax请求时传递的options参数
}
7.error
要求为Function类型的参数,请求失败时被调用的函数。该函数有3个参数,即XMLHttpRequest对象、错误信息、捕获的错误对象(可选)。ajax事件函数如下:
function(XMLHttpRequest,textStatus,errorThrown){
//通常情况下textStatus和errorThrown只有其中一个包含信息
this; //调用本次ajax请求时传递的options参数
}
8.async
要求为Boolean类型的参数,默认设置为true,所有请求均为异步请求。如果需要同步请求,请将此选项设置为false。
注意,同步请求将锁住浏览器,用户其他操作必须等待请求完成才可以执行。
[参考]()
[https://www.cnblogs.com/xmphoenix/archive/2011/11/21/2257651.html](https://www.cnblogs.com/xmphoenix/archive/2011/11/21/2257651.html)
[https://www.cnblogs.com/lengyuehuahun/p/5626668.html](https://www.cnblogs.com/lengyuehuahun/p/5626668.html)
## layer用法
### 1.layer提示框$.ajax({1
### 2.ajax请求后成功刷新页面,失败提示信息(使用layer组件)
type: “POST”,
data: json,
contentType: ‘application/json;charset=utf-8’,
url: “${ctx!}/admin/voucher/select/delete”,
success: function(msg){
}msg = JSON.parse(msg); if (msg.code == 0){ layer.msg(msg.message, {icon:1, time: 2000}, function () { window.location.reload(); //table.bootstrapTable("refresh"); }); } else { layer.msg(msg.message, {icon:2, time:2000}) }
});layer.confirm(‘是否确认删除?’, {btn: [‘确认’,’取消’]},1
2
### 3.layer确认框
function(){
},$.ajax({ type: "get", contentType: 'application/json;charset=utf-8', dataType: 'json', url: "${ctx!}/admin/warning/apply/del/" + id, success: function(msg){ if (msg.code == 0){ layer.msg(msg.message, {icon:1, time: 1000}, function () { $table.bootstrapTable("refresh"); // window.location.reload(); }); } else { layer.msg(msg.message, {icon:2, time:1000}) } } });
function () {
}
);layer.open({1
### 4.layer中打开网页
type: 2,
resize: true,
skin: ‘layui-layer-rim’, //加上边框
area: [‘1000px’, ‘800px’], //宽高
content: “http://www.baidu.com"
});1
2
3
### 5.关闭当前层var index = parent.layer.getFrameIndex(window.name); //先得到当前iframe层的索引 parent.layer.close(index);
1 |
|
{field: 'reason', title: '申请原因', align: 'center',
formatter: function (value, row, index) {
return '<input type="text" id="reason" data-index="'+index+'" onchange="changeReason(this)" value="'+value+'" />'
}
}
1 | ### 被修改后触发的监听事件: |
function changeReason(e) {
var value = $(e).val();
var index = $(e).attr("data-index");
dataList[index].reason = value;
}
1 | 其中dataList是一个全局变量 |
var dataList = [];
1 | ### 在数据加载成功时为其赋值: |
onLoadSuccess: function(){
dataList = $table.bootstrapTable("getData", true);
if(type == 2){
$table.bootstrapTable('hideColumn', 'abstractName');//隐藏abstractName列
}else {
$('#table').bootstrapTable('showColumn', 'abstractName');
}
}
1 | ### 提交动作: |
function saveOrSubmit(type) {
$.ajax({
type: "post",
url: "/admin/warning/apply/save",
data: {
saveType: type,
dataListStr: JSON.stringify(dataList),
bzy: $("#bzy").val(),
kj: $("#kj").val(),
cn: $("#cn").val(),
},
dataType: "json",
success: function (msg) {
// msg = JSON.parse(msg);
console.log(msg);
if (msg.code == 0) {
layer.msg(msg.message, {icon: 1, time: 2000}, function () {
var index = parent.layer.getFrameIndex(window.name);
parent.layer.close(index);
});
} else {
layer.msg(msg.message, {icon: 2, time: 2000})
}
}
});
}
1 |
|
var dataList = [];
var $table = $('#table');
var type = '${type}';
$table.bootstrapTable({
method: "POST",
url: "${ctx!}/admin/warning/apply/getConfirmCostApplicationList/" + type,
contentType: "application/x-www-form-urlencoded",
striped: true,
pagination: true,
pageSize: 1000,
pageList: [1000],
pageNumber: 1,
sidePagination: "server",
queryParamsType: "undefined",
paginationPreText: '上一页',
paginationNextText: '下一页',
height: $(window).height() * 0.58,
responseHandler: function (res) {
return {
"rows": res.content,
"total": res.totalElements,
};
},
columns: [
{field: 'subjectCode', title: '科目代码', align: 'center',},
{field: 'subject', title: '科目名称', align: 'center',},
{field: 'abstractName', title: '摘要', align: 'center',},
{field: 'limitAmount', title: '限制金额', align: 'center',},
{field: 'appliedAmount', title: '申请金额', align: 'center',},
{field: 'reason', title: '申请原因', align: 'center',
formatter: function (value, row, index) {
return '<input type="text" id="reason" data-index="'+index+'" onchange="changeReason(this)" value="'+value+'" />'
}
}
],
onLoadSuccess: function(){
dataList = $table.bootstrapTable("getData", true);
if(type == 2){
$table.bootstrapTable('hideColumn', 'abstractName');
}else {
$('#table').bootstrapTable('showColumn', 'abstractName');
}
}
});
function changeReason(e) {
var value = $(e).val();
var index = $(e).attr("data-index");
dataList[index].reason = value;
}
function saveOrSubmit(type) {
$.ajax({
type: "post",
url: "/admin/warning/apply/save",
data: {
saveType: type,
dataListStr: JSON.stringify(dataList),
bzy: $("#bzy").val(),
kj: $("#kj").val(),
cn: $("#cn").val(),
},
dataType: "json",
success: function (msg) {
console.log(msg);
if (msg.code == 0) {
layer.msg(msg.message, {icon: 1, time: 2000}, function () {
var index = parent.layer.getFrameIndex(window.name);
parent.layer.close(index);
});
} else {
layer.msg(msg.message, {icon: 2, time: 2000})
}
}
});
}
1 | 首先 |
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
/**
- 原生jdbc工具类,解决分片中间件无法调用存储过程
@author hql
*/
@Component
public class JdbcUtil {
@Value(“${jdbc.url}”)
private String url ;
@Value(“${jdbc.username}”)
private String username ;
@Value(“${jdbc.password}”)
private String password ;
private JdbcUtil(){}
public Connection getConn() throws SQLException {return DriverManager.getConnection(this.url,this.username,this.password);}
public void close(Connection conn){if (conn!=null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } }}
}1
2
application.properties中关于jdbc连接的参数配置#自定义jdbc连接
jdbc.url=jdbc:mysql://localhost:3306/db_name?useUnicode=true&characterEncoding=utf8&useSSL=true&rewriteBatchedStatements=true
jdbc.username=root
jdbc.password=xxxx1
2
返回单个值//注入工具类
@Autowired
private JdbcUtil jdbcutil;private String getCheckVoucherProcedureQuerySingleResult(
Long id, String types, Date startTime, Date endTime, String sharding) throws Exception { Connection conn = null; CallableStatement cs = null; String result; try { //通过工具类,获取数据库链接对象 conn= jdbcUtil.getConn(); cs = conn.prepareCall("{call InitForCreateTable(?,?,?,?,?,?)}"); cs.setLong("unitId",id); cs.setDate("endTime", (java.sql.Date) endTime); cs.setString("sharding",sharding); cs.registerOutParameter("result", Types.VARCHAR); cs.execute(); result = cs.getString("result"); } catch (Exception e) { e.printStackTrace(); throw new Exception("调用存储过程异常"); } finally { if(cs != null){ cs.close(); } jdbcUtil.close(conn); } return result;}
1
2
返回结果集public List
getDetailAccountProcedureProcedureQUeriesResultSet( String fiscalPeriod, Long unitId, String subjectCode, Date startDate, Date selectDate, Date endDate, String voucherT, Date topOneDate, int isZero) throws Exception { Connection con = null; CallableStatement cs = null; List<DetailAccountProcedure> resultSet = new ArrayList<>(); try { con = jdbcUtil.getConn(); cs = con.prepareCall("{call DetailAccountProcedure(?,?,?,?,?,?,?,?,?,?)}"); cs.setLong("unitId", unitId); cs.setString("sharding", fiscalPeriod); cs.execute(); ResultSet rs = cs.getResultSet(); while (rs != null && rs.next()) { DetailAccountProcedure result = new DetailAccountProcedure( rs.getLong("id"), rs.getDate("timer"), ); resultSet.add(result); } } catch (Exception e) { e.printStackTrace(); throw new Exception("调用存储过程异常"); } finally { if(cs != null){ cs.close(); } jdbcUtil.close(con); } return resultSet;}
1
2
3
4
5
6
## IDEA编辑器
### 控制台打印乱码问题
首先打开你自己的idea的安装目录下(即右键桌面图标,点击打开文件所在位置),然后找到idea.exe.vmoptions文件,用记事本打开,在最后一行填加:“-Dfile.encoding=UTF-8“,**但如果你的电脑操作系统是64位,那么请打开idea64.exe.vmoptions在最后一行填加。**
文件如下:-Xms128m
-Xmx750m
-XX:ReservedCodeCacheSize=240m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=50
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-Djdk.http.auth.tunneling.disabledSchemes=””
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-Dfile.encoding=UTF-81
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
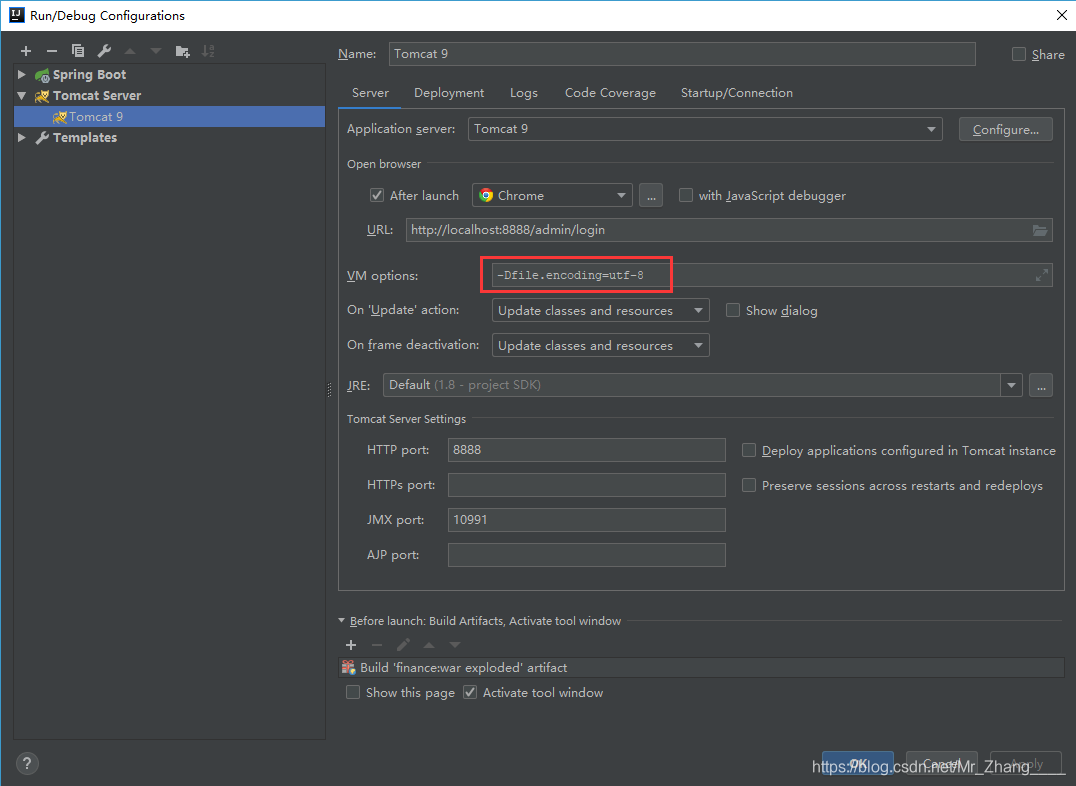
27然后设置IDEA server编码。在菜单栏找到"Run->EditConfigrations " 找到"Server"选项卡 设置 VM options 为 -Dfile.encoding=UTF-8,
如图所示:
**最后重启idea。**
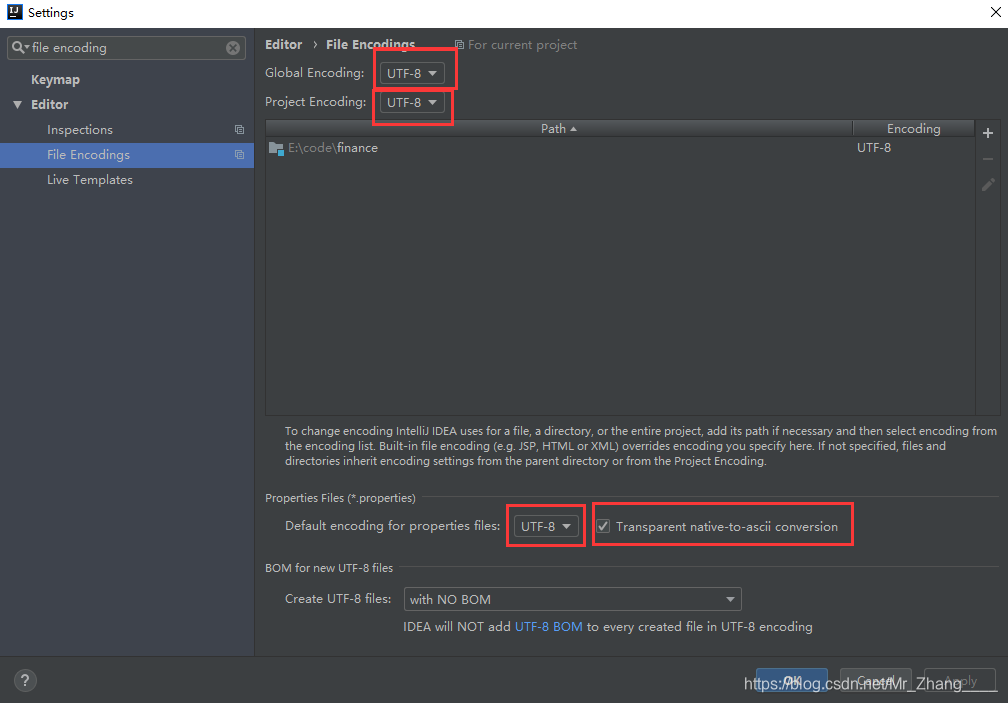
### 读取properties配置文件的中文乱码问题
具体步骤:
依次点击: File -> Settings -> Editor -> File Encodings(或者 File -> Settings 后搜索:File Encodings)
将页面顶端的Global Encoding和Project Encoding置为UTF-8
将Properties Files (*.properties)下的Default encoding for properties files设置为UTF-8,
将Transparent native-to-ascii conversion勾选上。
如图所示:
## 线上项目解决办法:
线上项目中使用向数据库中执行插入语句时出现乱码
在Tomcat -> bin -> catalina.bat 配置文件中,添加设置设置编码set JAVA_OPTS=%JAVA_OPTS% %JSSE_OPTS% -Dfile.encoding=UTF-8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
参考:
[https://blog.csdn.net/Java_wucao/article/details/78215173#commentBox](https://blog.csdn.net/Java_wucao/article/details/78215173#commentBox)
[https://blog.csdn.net/White55kai/article/details/71194664](https://blog.csdn.net/White55kai/article/details/71194664)
#### 添加新硬件
解决办法: 拆除新硬件重新开机,定位问题。
#### 内存条有灰尘
解决办法: 拆下内存条 擦拭金手指。
#### 风扇老化
解决办法: 更换风扇, 或者进BIOS查看,开机后按下DEL键进入BIOS选项,接着进入Power→Hardware monitor,我们会看到有三个选项CPU FAN SPEED;CHASSIS FANSPEED;POWER FAN SPEED,将CPU FAN SPEED项改成IGNORED,CHASSIS FANSPEED项改成N/A,POWER FAN SPEED项改成IGNORED。
#### 显卡驱动问题:
开机F8进入安全模式 --> 打开设备管理器 --> 禁用独显 --> 重新启动
重启后使用驱动软件(大师、精灵)重新安装显卡驱动,若不行则可能是显卡出现问题,可到维修电修理
参考:
[https://blog.csdn.net/hhxy_wlzx/article/details/78943294](https://blog.csdn.net/hhxy_wlzx/article/details/78943294)
# 游标是什么?
## 基本信息
游标(Cursor)是处理数据的一种方法,为了查看或者处理结果集中的数据,
游标提供了在结果集中一次一行或者多行前进或向后浏览数据的能力。
可以把游标当作一个指针,它可以指定结果中的任何位置,然后允许用户对指定位置的数据进行处理。
# 使用的方法定义游标
打开游标
循环遍历#具体操作关闭游标
1
2
# 代码示例CREATE DEFINER=
root@%PROCEDURECarryDown(
INunitIdbigint,
INshardingvarchar(255))
BEGIN
DECLARE id bigint;
DECLARE subject_code varchar(255);
DECLARE begin_balance decimal(16, 2) default 0.00;
DECLARE sumDebit decimal(16, 2) default 0.00;
DECLARE sumCredit decimal(16, 2) default 0.00;
DECLARE done INT DEFAULT false; – 自定义控制游标循环变量,默认false–SQL语句中强制规定游标的定义及其他变量都是在最开始定义的
DECLARE summary CURSOR FOR (SELECT s.id, s.subject_code, s.begin_balancefrom z_cashier_summary s WHERE s.unit_id = unitId AND s.year = sharding) ;– 绑定控制变量到游标,游标循环结束自动转true
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;OPEN summary; – 打开游标
summaryLoop:LOOP – summaryLoop为循环名--将当前游标得到的的变量赋值给自定义变量 FETCH summary INTO id, subject_code, begin_balance; IF done THEN LEAVE summaryLoop; --退出循环else
select ifnull(sum(d.borrow), 0.00), ifnull(sum(d.loan), 0.00) from z_cashier_data d where d.unit_id = unitId and d.abstract_code = subject_code into sumDebit, sumCredit; update z_cashier_summary s set s.debit_balance = sumDebit, s.credit_balance = sumCredit where s.id = id; -- 更新数据 END IF;END LOOP;
CLOSE summary; – 关闭游标
END1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
## Unknown column 'xxx' in 'field list'
多数是字段名错误,如果检查字段名没有问题 那就顺便检查一下表名吧 /哭笑
不知道你否同意,人都有惰性的说法,我这也是很同意的,有很多时候以此为借口,不运动,好吃懒做,直到我听说了一种说法,人的本性,其实和动物的本性差不多 - 生存。
下面是自己关于生存的一点思考
### 多吃少动
要生存,那么好吃不动,多吃可以囤积脂肪,脂肪可以抵御寒冷,这是祖先自保的有力手段。也是维持生存的两个最容易,也最有效的办法。
### 繁衍
说到繁衍,自然想到性,中国传统含蓄的教育让我很长一段时间里不敢提性,甚至谈“性”变色,王小波的书让我重新认识了性,现在已经可以很泰然自若的聊起这件事情,因为他不是见不得人的事,相反的是很平常的事情,往大了说因为有了性才有繁衍,有了繁衍才有文明,才有传承。往小了说性,或是性冲动都是作为一个正常人都因该有的东西,而且是一件让人兴奋的东西。当然除了王小波先生还有一些自己在网上探索努力。
### 狩猎
狩猎,发展到现如今的社会没有太多的狩猎机会,于是,运动取而代之。
#### 多巴胺
我总结的这三样东西都有一个共同的特点,那就是多巴胺。
吃东西,性,运动的过程都会产生多巴胺,所以我觉得我的总结不无道理。
数据库报错: The user specified as a definer (xxx@xxx) does not exist
原因:
视图或存储过程的定义者不存在
解决办法:
添加该用户或者修改用户为已有用户
参考: [https://yunzhu.iteye.com/blog/1168667](https://yunzhu.iteye.com/blog/1168667)
有时候看一本书被他的细节打动,一定是因为你在意过这个细节,所以你在阅读到作者写到的这个细节时会觉得很有共鸣,继而产生一种自我认同。所以很多时候我们觉得作者学的文章好,是因为他的细节描写的生动,其实也就是写出了你曾经历过但没有用语言表达过的东西。
### 文件属性
每个文件的属性由左边第一部分的10个字符来确定(如下图)。

从左至右用0-9这些数字来表示。
第0位确定文件类型,第1-3位确定属主(该文件的所有者)拥有该文件的权限。
第4-6位确定属组(所有者的同组用户)拥有该文件的权限,第7-9位确定其他用户拥有该文件的权限。
其中,第1、4、7位表示读权限,如果用"r"字符表示,则有读权限,如果用"-"字符表示,则没有读权限;
第2、5、8位表示写权限,如果用"w"字符表示,则有写权限,如果用"-"字符表示没有写权限;
第3、6、9位表示可执行权限,如果用"x"字符表示,则有执行权限,如果用"-"字符表示,则没有执行权限。
### chmod:更改文件9个属性
Linux文件属性有两种设置方法,一种是数字,一种是符号。
Linux文件的基本权限就有九个,分别是owner/group/others三种身份各有自己的read/write/execute权限。
先复习一下刚刚上面提到的数据:文件的权限字符为:『-rwxrwxrwx』, 这九个权限是三个三个一组的!其中,我们可以使用数字来代表各个权限,各权限的分数对照表如下:
r:4
w:2
x:1
每种身份(owner/group/others)各自的三个权限(r/w/x)分数是需要累加的,例如当权限为: [-rwxrwx---] 分数则是:
owner = rwx = 4+2+1 = 7
group = rwx = 4+2+1 = 7
others= --- = 0+0+0 = 0
所以等一下我们设定权限的变更时,该文件的权限数字就是770啦!变更权限的指令chmod的语法是这样的:
chmod [-R] xyz 文件或目录
选项与参数:
xyz : 就是刚刚提到的数字类型的权限属性,为 rwx 属性数值的相加。
-R : 进行递归(recursive)的持续变更,亦即连同此目录下的所有文件都会变更
举例来说,如果要将.bashrc这个文件所有的权限都设定启用,那么命令如下:
[root@www ~]# ls -al .bashrc
-rw-r--r-- 1 root root 395 Jul 4 11:45 .bashrc
[root@www ~]# chmod 777 .bashrc
[root@www ~]# ls -al .bashrc
-rwxrwxrwx 1 root root 395 Jul 4 11:45 .bashrc
那如果要将权限变成 -rwxr-xr-- 呢?那么权限的分数就成为
[4+2+1][4+0+1][4+0+0]=754。
[参考:https://www.w3cschool.cn/linux/](https://www.w3cschool.cn/linux/)
### 依次点击菜单:
build -> Build Artifacts -> Rebuild
### 等待进度条跑完后
会在项目文件的war包路径:
out -> artifacts
生成一个war包
### 将该war包放到Tomcat的webapps路径下,
### Tomcat检测到有新的包后会自动重启,
### 重启成功则服务发布成功。
推荐一个Win10的小程序
可以使任务栏透明,效果如下:

### 安装:
环境 win10
### 方式一:在应用商店中下载安装
- 打开开始菜单
- 输入store(或者“商店”)

- 打开商店搜索 translucentTB
- 选择安装
- 启动应用

### 方式二、在github上下载安装
- 打开[https://github.com/TranslucentTB/TranslucentTB/releases](https://github.com/TranslucentTB/TranslucentTB/releases)
- 下载下图.exe文件
- 运行exe文件后一直下一步
- 右键任务栏的TB图标,选择 regular -> clear

- 完成
### justify-content属性
justify-content属性定义了项目在主轴上的对齐方式。
.box {
justify-content: flex-start | flex-end | center | space-between | space-around;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21

它可能取5个值,具体对齐方式与轴的方向有关。下面假设主轴为从左到右。
- flex-start(默认值):左对齐
- flex-end:右对齐
- center: 居中
- space-between:两端对齐,项目之间的间隔都相等。
- space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
-
参考:
<a href="http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html" target="_blank">http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html</a>
### 实现makedown中在新页面打开标签
There is no such feature in markdown, however you can always use HTML inside markdown
#### 代码如下:
URL说明1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#### 效果如下:
<a
href="https://www.google.com"
target="_blank">
URL说明
</a>
参考:
<a
href="https://stackoverflow.com/questions/3492153/markdown-open-a-new-window-link/5803384"
target="_blank">
https://stackoverflow.com/questions/3492153/markdown-open-a-new-window-link/5803384
</a>
### scp 用于文件传输
使用方法:
scp [] source_file target_file – 第一个文件为源文件,第二个参数为目标文件1
2
示例:
scp root@zhangnlei.cn:/root/service/blog/nohup.out /home/zhang/log1
2
3
4
5
6
7
8
以上代码即将 zhangnlei.cn 服务器上的root用户的文件夹下的nohup.out文件拷贝到本地的log文件中
当然如果将两个参数的位置调换 那么就是将本地的文件上传到服务器中
总之是将文件从第一个参数的位置 传输到第二个参数的位置
常用参数:
-r 拷贝整个文件夹的内容
-P port指定传输使用的端口号1
2
3
4
参数说明:
-1: 强制scp命令使用协议ssh1
-2: 强制scp命令使用协议ssh2
-4: 强制scp命令只使用IPv4寻址
-6: 强制scp命令只使用IPv6寻址
-B: 使用批处理模式(传输过程中不询问传输口令或短语)
-C: 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
-p:保留原文件的修改时间,访问时间和访问权限。
-q: 不显示传输进度条。
-r: 递归复制整个目录。
-v:详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
-c cipher: 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
-F ssh_config: 指定一个替代的ssh配置文件,此参数直接传递给ssh。
-i identity_file: 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
-l limit: 限定用户所能使用的带宽,以Kbit/s为单位。
-o ssh_option: 如果习惯于使用ssh_config(5)中的参数传递方式,
-P port:注意是大写的P, port是指定数据传输用到的端口号
-S program: 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。1
2
3
4
5
6
7
8
9
10
参考:
<a
href="https://www.runoob.com/linux/linux-comm-scp.html"
target="_blank">
https://www.runoob.com/linux/linux-comm-scp.html
</a>
### 使用方法:
df [参数] [文件]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
### 示例:
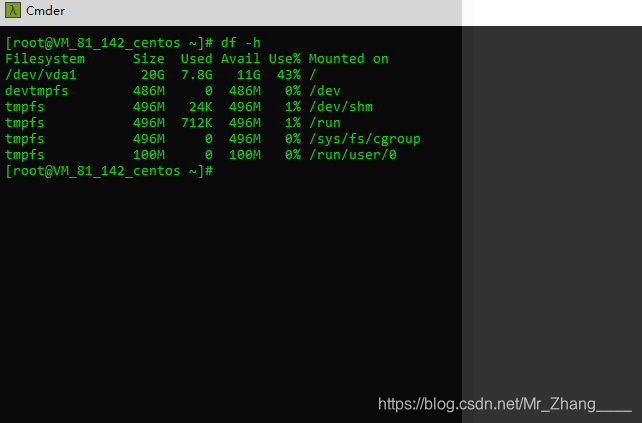
### 参数:
-h 适合人类观看的数据模式('8174556'的人类数据显示方式为'7.8G')
-a 全部文件系统列表
-H 等于“-h”,但是计算式,1K=1000,而不是1K=1024
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地文件系统
-m 区块为1048576字节
--no-sync 忽略 sync 命令
-P 输出格式为POSIX
--sync 在取得磁盘信息前,先执行sync命令
-T 文件系统类型
选择参数:
--block-size=<区块大小> 指定区块大小
-t<文件系统类型> 只显示选定文件系统的磁盘信息
-x<文件系统类型> 不显示选定文件系统的磁盘信息
--help 显示帮助信息
--version 显示版本信息
### 用法:
COALESCE(expression_1, expression_2, ...,expression_n)
### 解释:
依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。使用COALESCE在于大部分包含空值的表达式最终将返回空值。
#### 画外音
coalesce()函数像是ifnull()的升级版
### 需求:
点击一个输入框,弹出页面,在页面中填写表格数据,点击保存后关闭弹出页面,并将表格中汇总数据显示到最开始的输入框中。
### layer回调函数的实现思路:
在当前的DOM对象去找打开的iframe转成DOM对象调用子页面其中的函数
### 实现
js代码
function dateilSubsidyLayer(e) {
var $ids = $(e).prev();
var ids = $ids.val() == “” ? 0 : $ids.val();
layer.open({
type : 2,
area : [ ‘80%’, ‘80%’ ],
shift : 2,//可选动画类型0-6
scrollbar : false,
title : “补助费用明细”,
closeBtn : false,
content : “xxx/subsidy/“+ ids,
btn: [‘确定’,’取消’],
//这里yes:function为设置的第一个按钮的function,后面设置的按钮默认点击关闭
yes:function(index,layero){
//调用弹出iframe的函数 (callbackdata)
var obj = $(layero).find(“iframe”)[0].contentWindow.callbackdata();
//把回显的值赋给需要显示的地方
$(e).val(obj.money);
$ids.val(obj.ids);
//关闭弹出
layer.close(index);
}
});
}1
subsidy页面必须要有的function
var callbackdata = function () {
var obj = saveSubsidy(); //saveSubsidy()函数由具体业务逻辑确定故省略具体实现
return obj;
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198#### 分类
| | 可分享的(shareable) | 不可分享的(unshareable) |
| ------ | ------ | ------ |
| 不变的(static) | /usr(软件放置处) | /etc(配置文件) |
| | /opt(第三方软件) | /boot(开机与核心文件) |
| 可变动的(variable) | /var/mail(使用者邮件信箱) | /var/run(程序相关) |
| | /var/spool/news(新闻组) | /var/lock(程序相关) |
#### 详细

参考: [http://www.cnblogs.com/peida/archive/2012/11/21/2780075.html](http://www.cnblogs.com/peida/archive/2012/11/21/2780075.html)
一定要把你最宝贵的时间投入到可迁移的技能上。也就是说,在那些始终会用得到的技能上下最多的功夫,比如下面这些内容,可能会让你长期受用。
不要学习微服务框架,学习演进式架构(Evolutionary Architecture)。
不要学习新的编程语言,学习代码整洁之道、设计模式、领域驱动设计(DDD)。
不要学习 LeSS 和规模化敏捷框架(SAFe),学习精益生产原则(Lean manufacturing principles)。
不要学习 Hystrix,学习容错模式(Fault Tolerance Patterns)。
不要学习 Docker,学成持续交付。
不要学习 Angular、React 和 Vue,学习 Web、HTTP 和 REST。
忘记在哪里看到的了,侵删。
## HTTP请求与响应的过程
首先在浏览器输入www.163.com(url 统一资源定位符) 通过DNS解析获得IP地址,然后封装一个http请求
### Http请求的构建
| 请求行| 方法 | URL | 版本 ||
|---|----|-|--|-|
| 首部 | key|value|key|value|
|实体|
http请求包含三部分:请求行、首部、实体
#### 请求行:
1. 版本为http版本,如1.0, 1.1, 2.0
2. URL:即www.163.com
3. 方法:如get post put delete
#### 首部:保存重要的字段
例如:
- accept-charset 客户端可以接受的字符集
- content-type 正文的格式
- cache-control 控制缓存
### HTTP请求的发送
HTTP是基于TCP,所以使用面向连接的方式发送请求,通过stream二进制的方式传给对方,到了TCP层,二进制流转成报文段发送给服务器。
### HTTP返回的构建
| 状态行| 版本|状态码 | 短语 | |
|---|----|-|--|-|
| 首部 | key|value|key|value|
|实体|
#### 状态行
1. 状态码:如200 404
2. 短语:大概的原因
#### 首部:功能同上
- retry-after 稍后尝试
- content-type 返回类型:HTML,JSON
## HTTP进化历程
| |HTTP1.0|HTTP1.1|HTTP2.0|
|--|--|--|--|
|问题|客户端队首阻塞|服务端队首阻塞|
||对于同一个TCP连接,所有请求放到一个队列中,只有前一个请求的响应到了才能发送第二个请求|对于同一个TCP连接可以一次发送多个请求,解决了HTTP1.0的阻塞问题。但是规定服务器要按照接受顺序发送响应,先接受的请求的响应要先发送,那么此时就会出现一个问题,如果前一个响应的处理时间过长生成响应过慢,那么便会阻塞已生成响应的发送|无论是客户端还是服务端都不需要排队,同一个TCP有多个stream有各个stream发送和接收HTTP请求,相互独立,互不阻塞|
### HTTP2.0的提升性能的优化思路
1. 头压缩:使用索引表的方式,将每次搜药携带的大量key-value在两端建立索引表,对相同的头只发送索引表中的索引
2. 分帧
3. 二进制编码
4. 多路复用技术
## 基于UDP的QUIC协议
(我猜quic是quick快速的缩写)
Google的QUIC协议
- 自定义连接机制:源IP,源端口,目的IP,目的端口一个元素发生改变时TCP便会断开连接,重新连接。WiFi或移动网络切换时会导致重连,导致时延。基于UDP的连接不以四元组标识,而是以一个64位的随机数作为ID。
- 自定义重传机制:修复TCP中的采样往返时间RTT不准确的问题
- 无阻塞的多路复用:同HTTP2.0一样,同一条连接可以建立多个stream来发送HTTP请求。由于QUIC是基于UDP的,一个连接上的stream没有依赖,这样假如stream2丢包,需要重传,后面的stream3无需等待就可以发送诶用户。
- 自定义流量控制:TCP流量控制是基于滑动窗口协议,起点是下一个要接受并且ACK的包,及时后面的包到了放在缓存里窗口也不能右移。
[image](https://static001.geekbang.org/resource/image/a6/22/a66563b46906e7708cc69a02d43afb22.jpg)
而QUIC是基于offset,包来之后进入缓存便可应答,且不但在一个连接上控制窗口,还在一个连接的每一个stream控制窗口
看过很多遍的电影《搏击俱乐部》,男主喜欢做一件事情叫活人献祭(可能翻译的有些问题)。
晚上来到一个24小时便利店,把店员拖到后门,让他背对跪下,用枪指着脑袋,威胁说要一枪从脑后把他的脸轰烂。
问他以前的想做什么,店员说想做兽医,又问他为什么没有去做,店员说因为有很多东西要去学。
男主留下他的驾驶证,说六周后如果没有努力做兽医还会来找他。
旁边的人问,你为什么这样做?男主说:明天早上,雷蒙(店员)的早餐会比任何人吃的都香。
-
看这一段时真的...浑身起鸡皮疙瘩。
为了目标或者说梦想去努力的时候吃饭很香,做事充满干劲,每一天都会很充实。雷蒙会不会成功不一定,但是他肯定会觉得以后的人生充满希望。
不是说兽医要比店员更高级,而是每天的生存状态都不一样。
可能这就是梦想的魅力。
如果每天都被苟且之事所叨扰,那就停下来想想的梦想。
# Java的内存模型
引子
操作系统中硬盘存放输数据,CPU处理数据。
由于摩尔定率,CPU的运算速度不断上升,而硬盘的读取速度有限,所以引入了内存机制。
内存机制便是用来协调两者的速度,将CPU需要用到的数据或处理完的数据先存入内存中,然后在进行IO操作。从而一定程度上加快了整体的处理速度。
随着时间推移,CPU的速度又提升了,内存的读写速度夜跟不上了,于是便有了高速缓存机制。
高速缓存的作用和内存是一样的,也是用来协调CPU与内存的读写速度。
后来摩尔定律被打破,interCEO下跪,推出了多核CPU来增加算力。且每个核心的CPU都有一个自己的高速缓存。
此时的高速缓存也出现了一个问题就是,如果主存中的数据在一个高速缓存中被修改,那么如果没有及时的同步到内存中,那么便会出现数据的异常。
说起Java的内存模型,和操作系统的这个机制很相像。
## Java的内存模型分为线程私有,线程共享空间。
线程私有包含 虚拟机栈、本地方法栈、程序计数器。
线程共享包含方法区、堆。
### 线程私有
#### 虚拟机栈 :
存储局部变量表,操作数,动态链接,方法出口。
#### 本地方法栈:
与虚拟机栈相似,为本地方法服务
#### 程序计数器:
存放下一条要执行的指令的地址。
### 线程共享
#### 方法区:
存放加载的类信息,常亮,静态变量。
#### 堆:
存放对象实例,是Java虚拟机中占用内存最大的一块 。
# ARTS计划
`张念磊 2020/1/16 `
响应左耳听风专栏号召,本人愿每周完成一个ARTS:
> Algorithm:每周至少做一道LeetCode的算法题,保持训练和学习。
> Review:每周阅读并点评一篇英文的技术文章,主要是为了学习英文。
> Tip:学习至少一个技术技巧,总结和归纳日常生活中遇到的知识点。
> Share:分享一篇有观点和思考的技术文章,适当输出以获得反馈。
2020年第三周开始

详情链接:[https://time.geekbang.org/...](https://time.geekbang.org/column/article/85839)
[TOC]
## 1. 处理问题的思路
1. 出问题,`看日志`
2. `分析`具体有什么错误
3. 针对错误`解决问题`
## 2. 具体步骤
`查看日志`
```shell
cat /var/log/mysqld.log
或者使用less,tail 命令,根据具体场景选择。warning和note不用管,直接看error
1 | 2018-08-21T12:41:21.480445Z 0 [ERROR] Can’t start server: Bind on TCP/IP port: Address already in use |
意思是3306端口占用
那么就查看哪些应用占用了端口,是不是服务已经启动,或者其他服务占用端口
1 | lsof -i:3306 |
或者
1 | netstat -anp|grep 3306 |
根据自己的需求(不是生产环境可以随意玩)可以直接kill该进程
1 | kill -9 xxx |
然后重启服务
1 | service mysqld restart |
3. 可能的问题
例子1:
启动时报错
1 | Redirecting to /bin/systemctl start mysqld.service |
Job for mysqld.service failed,MySQL服务启动失败。
可能的原因是是:
- 端口占用
- 配置文件有错误(可能刚改过配置文件)
例子2:
连接时报错:
1 | ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2) |
连接不到,可能的原因:
- 一般是mysql没有启动或者启动失败
- 如果服务已启动,可参考 https://www.2cto.com/databa…
4. 参考
Linux起源
操作系统出现时间线:
Unix1970年诞生 ,71年用C语言重写
Apple II 诞生于1976年
window诞生于1985年
Linux诞生于1991年,由大学生Linus Torvalds和后来的众多爱好者共同开发完成。
想必大家看了这个时间线应该能想明白为啥Linux要出现并且开源吧。因为前面三个都贼贵。
为什么是企鹅logo

因为企鹅是极地动物,极地(南极北极)又不属于任何一个国家,所以代表Linux不属于任何商业公司,是一个开源的东西,所有人都可以免费试用。
开源协议
Linux 最大的优势当属它的开源属性。Linux 是一款基于 GNU 通用公共许可证(GPL)发布的操作系统。这意味着,所有人都能运行、研究、分享和修改这个软件。经过修改后的代码还能重新分发,甚至出售,但必须基于同一个许可证。这一点与传统操作系统(如 Unix 和 Windows)截然不同,因为传统操作系统都是锁定供应商、以原样交付且无法修改的专有系统。
注:在谈到 Linux 时,人们对其含义的理解常有不同。特此声明,我们这里所谈的,是 Linux 内核及其捆绑的工具、应用和服务。这些要素共同构成了这个功能强大的操作系统,大多数人称之为“Linux”。自由软件基金会则将其称为“GNU/Linux”,因为其中的部分工具、应用和服务是 GNU 系统的组件。这些组件已与 Linux 内核捆绑,所以我们所熟知的 Linux 所指的不仅仅是 Linux 内核本身。
Redhat为什么是一家收费的商业公司?
通过出售组装了Linux内核和自研软件服务方式实现收费。
注意事项
- Linux是区分大小写的
- Linux 中的东西都是文件形式保存,包括硬件
- Linux没有扩展名这个概念
- Windows早起的8.3规则 文件名不超过8位,点后的格式不超过3位,现已废弃改规则
- Linux不考扩展名区分文件类型
- 压缩包:.gz/.tar/.bz/.tar.bz2/.tgz
- 二进制软件包:.rpm
- 网页文件:.html/.php
- 脚本文件:.sh
- 配置文件:.conf
- Linux所有的设备必须挂载之后才能使用
服务器管理和维护建议
Linux各个目录的作用
- bin
- boot
- etc
- home
- lib
- lost+found
- media 挂载多媒体服务
- mnt U盘
- misc
- opt
- usr/local 把第三方软件安装的位置
- proc 虚拟文件目录
- sys 保存在内存中,
- root
- srv
- tmp
- usr
- var
- 不允许关机只允许重启
- 重启时关闭服务
- 不要再服务器高峰运行高负载命令
- 配置防火墙时不要把自己踢出服务器
- 密码规范 定期更新
- 合理分配权限
- 定期备份重要数据和日志 备份的原则就是“不要把鸡蛋放在一个篮子里”
Linux常用命令
本文主要以学习ls命令为例讲解Linux命令的学习方法
命令格式
命令格式:命令 【-选项】【参数】
例如:
1 | ls -la /etc |
说明:
1)个别命令不使用此格式
2)当有多个选项时,可以写在一起
3)简化选项和完整选项
-a 等于 --all
如何学习一个命令:
从以下几个方面:
命令名称:ls
命令英文原意:list
命令所在路径:/bin/ls
执行权限:所有的用户
功能描述:显示目录文件
语法:ls 选项[-ald] [文件或目录]
-a 显示所有的文件,包含隐藏文件 all
-l 显示详细信息 long
-d 查看目录属性
补充:1、隐藏文件
什么是Linux的隐藏文件?
Linux隐藏文件:使用ls命令不显示的文件 需要使用ls -a 命令显示,Linux中前缀为点(.)的文件就是隐藏文件,比如.bash_profile ,.cshrc
如何隐藏:想隐藏一个文件,将文件改名,在最前面添加.
引用计数 | 所有者 | 所属组 | 文件的大小 | 文件最后修改的时间 | 文件名
补充:2、解释使用ls -l查看到的文件信息
1 | [root@VM_81_142_centos ~]# ls -l |
所有者只有一个,所属组只能有一个,剩下的全都叫其他人。
1 | drwxr-xr-x |
第一位
1 | d 表示目录 |
剩余九位表示每三位分别表示【 所有者 | 所属组 | 其他人】的权限
rwx r-x r-x
其中
1 | r 读取权限 |
目录处理命令
mkdir
英文名称:make directories
命令所在的路径:/bin/mkdir
执行的权限:所有用户
语法:mkdir -p [目录名]
功能描述:创建新的目录
-p递归的创建
范例:
1 | mkdir -p /tmp/japan/boduo |
cd
英文原意:change directory
命令所在路径:shell内置命令
执行权限:所有用户
功能:功能切换目录
范例:
1 | cd /tmp/Japan/boduo # 进入文件夹 |
rmdir
命令英文:remove empty directories
命令所在的路径:/bin/rmdir
执行的权限:所有用户
功能描述: 删除空目录
语法:rmdir [目录名]
范例:
1 | rmdir /tmp/japan/boduo |
cp
命令英文 copy
命令所在的路径:/bin/cp
执行的权限:所有用户
语法:cp -rp [元文件或目录] [目标目录]
-r 复制目录
-p 保留文件属性
功能描述:复制文件或目录
可以同时复制多个目录
1 | cp cangjing longze xiaoze /tmp/Japan # 复制三个文件到文件夹 |
可以复制到同时改名
1 | cp -r cangjing /tmp/Japan/canglaoshi |
mv
英文原意:move
命令所在路径:/bin/mv
执行权限:所有用户
语法:mv [源文件或目录] [目标目录]
功能描述:剪切文件、改名
rm
英文原意:remove
命令所在的路径:/bin/rm
执行权限:所有用户
语法:rm -rf [文件或目录]
-r 删除目录
-f 强制删除
功能描述:删除文件
文件处理命令
@auther 张念磊
@date 2020/1/29
touch
命令所在路径:/bin/touch
执行权限:所有用户
语法:touch [filename]
功能描述:创建空文件
范例:
1 | touch Japanlove.list |
cat
语法:cat [filename]
功能描述:打印文件内容
范例:
1 | cat /tmp/boduo |
带有行号的显示:
1 | cat -n /tmp/boduo |
tac
语法:tac [filename]
功能描述:倒序打印文件内容
范例:
1 | tac -n /tmp/boduo |
more
功能描述:分批次查看文件
语法:more [filename]
范例:
1 | more /tmp/boduo |
功能键:
空格 - 翻页
enter - 下一行
less
功能简述:功能类似more命令,比more命令多两个功能,上翻页和搜索
语法:less /tmp/boduo
参数:
-m 显示百分比
-N 显示行号
功能键:
f:下一页
b:前一页
/关键词 :搜索关键词
?关键词:向前搜索关键词
n:显示匹配的下一个
N:显示匹配的上一个
head -n
功能描述:查看文件头部(默认10行)
语法:head /etc/cangjing
参数:
-n 8 查看前8行
示例:
1 | head -n /etc/cangjing |
tail
功能描述:查看文件尾部(默认10行)
语法:tail /etc/cangjing
参数:
-f 动态显示
示例:
1 | tail -f cangjing |
http://www.zhangnlei.cn/article/54
LeetCode看到一个小技巧
很有趣,记录一下。
算法题中困难的地方就是面对复杂的情况,找出一个公共的方法
以下是一个题解中的代码片段:1
2
3
4
5
6
7
8
9public static void functionName (int[] nums1, int[] nums2){
int n1 = nums1.lenght;
int n2 = nums2.lenght;
if (n1 > n2){
functionName(nums2, nums1);
}
....
// 算法代码
}
巧妙,优雅,有意思。
firewall使用指南
@auther 张念磊
@date 2020/2/9
firewall是什么?
Centos7 默认的防火墙是 firewall,替代了以前的 iptables
2、firewall 使用更加方便、功能也更加强大一些
3、firewalld 服务引入了一个信任级别的概念来管理与之相关联的连接与接口。它支持 ipv4 与 ipv6,并支持网桥,采用 firewall-cmd (command) 或 firewall-config (gui) 来动态的管理 kernel netfilter 的临时或永久的接口规则,并实时生效而无需重启服务。
如何安装?
1)像使用 iptables 一样,firewall 同样需要安装
2)需要注意的是某些系统已经自带了 firewal l的,如果查看版本没有找到,则可以进行 yum安装
3)安装指令: yum install firewalld
如何使用?
示例开启80端口
1 | firewall-cmd --zone=public --add-port=80/tcp --permanent |
重新启动防火墙
1 | firewall-cmd --reload |
参数说明:
–zone 作用域
–add-port=8080/tcp 添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
在指定区域开启某个范围的端口号
(如18881~65534,命令方式)
1 | firewall-cmd --zone=public --add-port=18881:65534/tcp --permanent |
参数
| 参数 | 作用 |
|---|---|
| –version | 查看版本 |
| –get-active-zones | 查看区域信息 |
| –state | 查看防火墙状态 |
| –get-default-zone | 查询默认的区域名称 |
| –set-default-zone=<区域名称> | 设置默认的区域,使其永久生效 |
| –get-zones | 显示可用的区域 |
| –get-services | 显示预先定义的服务 |
| –get-active-zones | 显示当前正在使用的区域与网卡名称 |
| –add-source= | 将源自此IP或子网的流量导向指定的区域 |
| –remove-source= | 不再将源自此IP或子网的流量导向某个指定区域 |
| –add-interface=<网卡名称> | 将源自该网卡的所有流量都导向某个指定区域 |
| –change-interface=<网卡名称> | 将某个网卡与区域进行关联 |
| –list-all | 显示当前区域的网卡配置参数、资源、端口以及服务等信息 |
| –list-all-zones | 显示所有区域的网卡配置参数、资源、端口以及服务等信息 |
| –add-service=<服务名> | 设置默认区域允许该服务的流量 |
| –add-port=<端口号/协议> | 设置默认区域允许该端口的流量 |
| –remove-service=<服务名> | 设置默认区域不再允许该服务的流量 |
| –remove-port=<端口号/协议> | 设置默认区域不再允许该端口的流量 |
| –reload | 让“永久生效”的配置规则立即生效,并覆盖当前的配置规则 |
| –panic-on | 开启应急状况模式 |
| –panic-off | 关闭应急状况模式 |
其他命令
| 命令 | 解释 |
|---|---|
| firewall-cmd –zone=public –list-all | 查看公开区域的信息 |
| Firewall-cmd –list-all-zone | 查看所有区域的信息 |
| firewall-cmd –zone=public –list-ports | 查看指定区域所有开启的端口号 |
| systemctl start firewalld | 开启防火墙 |
| systemctl stop firewalld | 关闭防火墙 |
| systemctl enable firewalld | 设置开机启动 |
| sytemctl disable firewalld | 停止并禁用开机启动 |
| firewall-cmd –reload | 重启防火墙 |
| /etc/firewalld | 配置文件的路径 |
参考
后端 - Git学习分享
@auther 张念磊
@date 2020/2/17
一个学习git的网站
https://learngitbranching.js.org/
1 | 基础 |

示例 : 把分支以图像的方式展现给用户

通关截图

主要介绍的两个命令 rebase cherry-pick

配置别名
有没有经常敲错命令?比如git status
如果敲git st就表示git status那就简单多了,当然这种偷懒的办法我们是极力赞成的。
我们只需要敲一行命令,告诉Git,以后st就表示status:
1 | $ git config --global alias.st status |
好了,现在敲git st看看效果。
当然还有别的命令可以简写,很多人都用co表示checkout,ci表示commit,br表示branch:
1 | $ git config --global alias.co checkout |
提交就可以简写成:
1 | $ git ci -m "bala bala bala..." |
--global参数是全局参数,也就是这些命令在这台电脑的所有Git仓库下都有用。
git log

甚至还有人丧心病狂地把lg配置成了:
1 | git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit" |
来看看git lg的效果:

代码展示
1 | watchScroll() { |
使用说明
第三行中的
discussInfoBox为要监听的div的ID在第十行编写当滚动条滚动到最下方时需要调用的函数
在需要的地方调用该函数。例如created方法或其他监听事件中
阅读本文需要大约3分钟
为什么要使用GitHub Page搭建博客?
关键词:Hexo 、GitHub Page、Typora、Blog
对于我的个人博客,我一直没有停下折腾的脚步,最早的博客是大二时搭在腾讯云学生服务器上,后面也尝试了CSDN,cnblog,简书,掘金等博客平台,下面是我做的一个简单地分析对比:
博客平台简分析对比
几大平台中
CSDN的SEO做的最好,访问量最多的能有7000+ https://blog.csdn.net/Mr_Zhang..在博客平台发布文章需要审核,审核时长不定,且有一定的几率会不过审,自己搭建的博客则无需审核机制。
- 自己搭的博客是发布在的自己的腾讯云云服务器上的,网址: zhangnlei.cn。博客服务需要自己发布,云服务器需要定期维护,对个人来说是需要不小的时间成本和金钱投入。(我的博客服务是GitHub上找的一个开源项目,删删改改,为自己所用)
- 因为网页的编辑器不是很稳点,我写博客一般都是先在本地写好Markdown,然后在贴到博客的编辑器中,再添加标签、分类等,最后再发布。需要很多重复工作。
综上:自己的服务器有一定的服务维护成本,博客平台编辑体验不佳、自由度不高。
所以决定尝试使用GitHub Page+Hexo搭建了自己的博客,优点有以下:
使用GitHub+Hexo搭建博客的优点
- 无需维护服务器,服务是挂载在github的服务器上,由github维护(现由微软收购),维护成本几乎为0,且足够稳定。
- 自由度高,发布的内容随心而定,无需受平台的限制。
- 编辑体验好,无需反复搬运文本,打标签等,搭配软件Typora在本地编写MarkDown,博客编写完后一行命令一秒发布,契合程序员的操作体验。
当然也有缺点:对非开发者来说需要一定的门槛,可能连GitHub是什么都不知道。
好下面简单介绍一下我使用到的工具和服务:
使用到的工具和服务
Hexo是一个非常成熟的博客框架,可以根据用户编辑的Markdown文件生成静态的htnl文件。当然用户可以选择自己喜欢的主题插件安装,以生成优美博客界面。
GitHub提供了一个GitHub Page的功能,每个用户都可以有一个属于自己域名的静态页面。
Typora软件,本地编写md文件,实时编写实时渲染,使用体验极佳。
于是使用Hexo + GitHub Page便可搭建一个免费的个人博客,搭配Typora在本地编写MarkDown,舒适度不要太高。
有了上面的工具做基础,实现起来就很简单啦,具体的步骤就不详细说明了,网上一搜一大把。
这里提供几个搜索的关键词:github.io/github page/hexo/个人博客。
安装过程并非一帆风顺,好在hexo技术和社区非常成熟,官方有文档、网络上也有非常多帖子。
成果展示
我选用的Hexo主题是Vue风格的vexo主题,干净简单。本人比较喜欢Vue的主题,Typora用的也是类Vue的主题。
上一张博客zhangnlei.github.io的效果图:

下图为Typora软件截图:

是不是都很VUE。哈哈
写在最后
以后会在这里记录一些心情、读书笔记、编程技术分享之类的文章。
感谢阅读。
@auther 张念磊
@date 2020/5/18
我的偶像:
对我影响很深的两个人 一个是篮球巨星 - 科比,另一个是苹果的创始人CEO - 乔布斯。
我喜欢他们的基础是我对他们非常的了解,越了解越能发现他们身上的闪光点,就越喜欢越欣赏。
我在我的高中时代读了《乔布斯传》,每天晚上在被窝里拿着一个砸脸很痛的MP4,劣质的屏幕、刺眼的光,我永远忘不了那个时候读到激动处全身的颤抖。
我不知道你是否了解科比?单纯的觉得他就是努力的代名词。科比非常的聪明,当然他也足够简单、执着。
你可能听过他说的“凌晨四点的洛杉矶”,但他并不是从凌晨四点开始一直训练练到晚上。他的时间安排精力管理能力都非常的惊人,让我受益良多。
科比
(你不需要喜欢打篮球,也不需要看篮球比赛。因为你知道的我也不是多喜欢篮球,我只是单纯的喜欢科比这个人,还有他的曼巴精神)
视频链接1:【科比TED:意志的力量】科比的意志力到底有多强?
科比给我的启示
一、面对问题时的态度
不放弃尝试的权利。因为做和不做的差别太大了:
- 体验,做了才有资格评论;
- 成长,去做一件事情肯定是先了解原理,然后实践,最后总结。如果你做都不去做,连原理都不了解,那就对这一块永远都不了解,所以尝试最差的结果也是收获知识,填补知识盲区。
- 一旦开始做了,就相信自己一定做到。只有这样才能让自己全力以赴。想尽办法、详细的规划、问题分为几个阶段,然后一个阶段一个阶段的去完成。同时每一阶段都专注于这一阶段该干的事情。
二、精力和时间管理的方法
时间是有限的,精力也是。一定是把最好的状态给到最重要的事情。
对此,我有很多自己的小方法:晚上会找好第二天穿的衣服,这样第二天早上就不用思考这种穿衣问题。
同样的原理,安排琐碎的事情也可以用同样的方法:比如三餐吃什么,我会用随机软件(小程序),减少决策的成本。
视频链接2:【第四个视频】迈克尔·乔丹落泪深情缅怀科比:你走了,一部分我也死了
【视频链接2中的第一个视频】:总是逃避各种事情?心理学家:别藏了,你比想象的更强大
视频链接3: 解读《被讨厌的勇气》学习阿德勒的人生哲学!
关于梦想,关于使命感
乔布斯
视频链接4:乔布斯在斯坦福大学毕业典礼上的演讲
If you haven’t found it yet, keep looking, and don’t settle.
你们如果还没有发现自己喜欢什么,那就不断地去寻找,不要祈求安逸
以下为两段摘抄 - 链接: http://www.zhangnlei.cn/article/61
如何做梦
“梦 - Lil Jet” 18岁的rapper也可以有自己的梦,这首歌表达出的便是他自己的梦。
我们不评判这个梦的大小,高尚与否,关键是:有了梦,生活工作才有灵魂。
我对于梦想的追寻
乔布斯的演讲中的一句话:If you haven't found it yet, keep looking, and don't settle. 是如何拥有梦想这个问题最好解答。
我给自己找了一个梦想,35岁,40岁,,
我在35岁40岁后面加的是逗号,那个东西不是我梦想的终结,更不是我人生的终结。人生是一场修炼,我的使命感让我觉的我要做的远不止于此,但是那是我当前想到的最伟大的梦想了。
很具体的东西
孔老夫子:修身齐家治国平天下,修身而后齐家,齐家而后治国,治国而后平天下。这是一个递进的关系,所以我没有办法在自己都没修炼好的时候就想着影响其他的人,因为我不知会把人往好的方向引导还是坏的方向引导。
所以据其位谋其事,我当前就是在修身的阶段。
我觉得梦想是非常珍贵的东西。他有很多作用,比方说梦想可以持续的激励我,激励我变强,激励我广博的获取知识,持续学习,保持初心。
他可以让我更容易管理我自己,看什么样的书,交什么样的朋友
当然有助于我做选择,我现在的选择标准很简单,如果这件事情有助于我梦想的实现,能让我离我的梦想更进一步,那我就义无反顾的去做。不用过多的纠结利弊分析,先做了再说。
我的方法论
“想成为什么样的人,那就先做他做的事。” 这是我追梦的方法。当然要抓住本质,不能只学表面,东施效颦,得不偿失。
最后
以上便是我近几年来对于梦想、对于修炼的看法。 如果能对你找到梦想有一点帮助,便很开心了。
视频链接:乔布斯在斯坦福大学毕业典礼上的演讲
以下为两段摘抄:
You’ve got to find what you love, and that is as true for work as it is for your lovers.
Your work is going to fill a large part of your life, and the only way to be truly satisfied is to do what you believe is great work, and the only way to do great work is to love what you do.
工作将是生活中的一大部分,让自己真正满意的唯一办法,是做自己认为有意义的工作。做有意义的工作的唯一办法,是热爱自己的工作
If you haven't found it yet, keep looking, and don't settle.
你们如果还没有发现自己喜欢什么,那就不断地去寻找,不要祈求安逸As with all matters of the heart, you’ll know when you find it, and like any great relationship it just gets better and better as the years roll on.
就像一切要凭着感觉去做的事情一样,一旦找到了自己喜欢的事,感觉就会告诉你。就像任何关系一样,都会随着时间的推移建立起来。Your time is limited, so don’t waste it living someone else’s life. Don’t be trapped by dogma, which is living with the results of other people’s thinking.
你们的时间都有限,所以不要按照别人的意愿去活。不要让别人思想里盲从的信条困惑你Don’t let the noise of others’ opinions drown out your own inner voice,
不要让别人观点的聒噪声淹没自己的心声And most important…have the courage to follow your heart and intuition.
最主要的是,要有跟着自己感觉和直觉走的勇气They somehow already know what you truly want to become.
无论如何,感觉和直觉早就知道你到底想成为一个什么样的人,Everything else is secondary.
其它的都不重要And I have always wished that for myself, and now, as you graduate to begin a new, I wish that for you.
Stay hungry, stay foolish.
我总是以此自许。当你们毕业,展开新生活,我也以此期许你们:求知若饥,虚心若愚。
名人自传、访谈 - 很少抱怨,很少找借口。
而大多数人都喜欢推卸责任,因为人会有推卸责任的习惯,会找那些经历来解释当前的状态,把过去搬出来解释自己现在,把不幸当成自己的借口,推卸自己的责任
怎么做:
没有必要把活着的经历去纠结那些完全无法改变的事,但是我们完全有能力去改变现在呀,从而去影响明天。
阿德勒认为,我们成年后,就要为自己的行为负责,为自己的人生负责。
我们每时每刻都在做选择,读什么样的书?看什么样的剧?听什么样的歌?关注哪些人?和谁去结婚?做什么样的职业?甚至每天的时间是如何安排的?精力主要用在了什么地方?
这一切都是自己的选择,是自己一次又一次的义无反顾的选择,把你送到了现在的位置、达到了现在的状态。
无需抱怨自己拿到了什么样牌,而是考虑如何打好现有的牌,这才是务实有建设性人生态度。
没有谁的人生是完美后才出发的
承认自己的不足需要勇气,但这也是进步的开始。
先听一遍,消化一下;
然后提出一些问题,带着问题再听一遍;
第二次听的时候记下问题的关键词,然后尝试整理成通顺的语言和要点。
通读一遍自己整理的,如果还有问题,再听一遍,完善。
给朋友讲述自己的成果,讲述过程中有新发现或没讲明白的再思考,然后研究一遍。(此时可能音频里讲到的已经不能解答你了,要自己去寻找答案了)
达成读书的最终目的 - 思考;
结合理论“费曼学习法”
前端开发 - js未发布的新特性-避免js链式调用时的‘age’ of undefined 异常
可选链式调用
1 | let name = movie.director?.name; |
如果不存在属性 则返回undefined,不会报错。
无效值合并操作符
表达式variable ?? defaultValue会在variable为undefined或null的时候把defaultValue的值赋给variable。
1
2
3
4
5 const noValue = undefined;
const value = 'Hello';
noValue ?? 'Nothing'; //=> 'Nothing'
value ?? 'Nothing'; //=> 'Hello'
扫描二维码,分享此文章